Polynomial basis expansion, also called polynomial features augmentation, is part of the machine-learning preprocessing. It consists in adding powers of the input’s components to the input vector.
Example
Let be a dataset for a machine-learning task. As usual, is made of pairs of input vectors and output value :
For clarity, suppose the dimensionality is two: .
The polynomial augmentation of degree for the input vector :
Is the vector :
Likewise, the degree augmentation is:
and so on…
Polynomial regression and linear models
Polynomial inputs augmentation enriches the expressive power of linear models. Indeed, a polynomial regression of degree is simply a linear regression on the augmented inputs.
In other words, to fit the polynomial :
To a dataset , it is enough to fit a linear function to the augmented dataset:
This is why a polynomial regression is a linear regression.
Notations
To keep the notations simple, we often consider that the polynomial inputs augmentation is done in the preprocessing and we note to denote the augmented vector .
How much richer does linear regression become?
Very much! By the Stone-Weierstrass theorem (wikipedia link), every continuous function can be uniformly approximated (as closely as desired) by a polynomial function on a closed interval.
Since our dataset is discrete, this means that whatever the relationship between the inputs and the outputs, we can get as close as we want using polynomials (as long as the degree is big enough).
Actually, since the train set is finite, we can always find a polynomial of degree that goes through every points in the train set. This means that for , we can make the train error to be . This is called the Lagrange polynomial interpolation (wikipedia link).
Wait… we can make the train error to be ? Yes, but…
So, is it the ultimate machine-learning technique?
No, because…
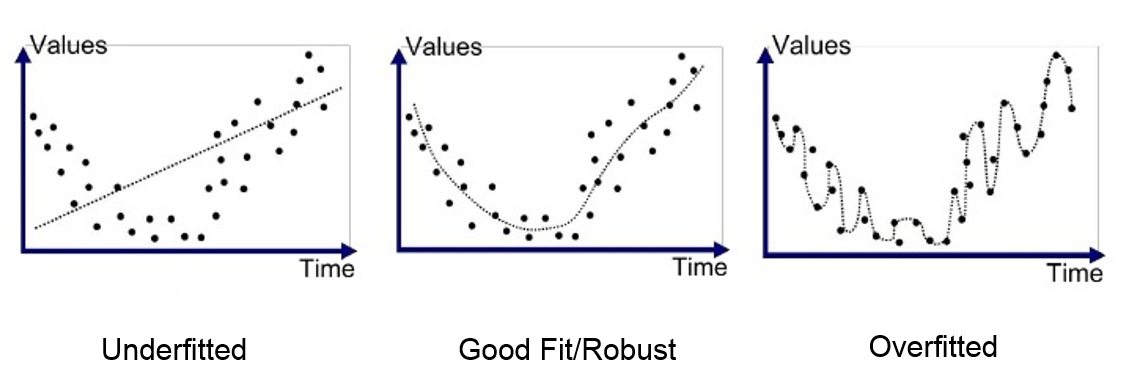
Polynomial regressions of high degree tend to overfit. If you’re not sure what that means, check out my dedicated article, which is completely writen and illustrated using polynomial regressions: overfiting.
The regression matrix that we have to inverse grows linearly as the regression’s degree grows (since it has rows). This yields computational complications.
Numerical errors accumulate when we take the power of a number: large powers of small values are rounded to in floating point arithmetic. So even is there exists a mathematical solution, we might not be able to implement it.
How to improve polynomial regressions?
- To mitigate overfitting, we can use regularization. For instance, a ridge regression or a lasso regression.
- To find the best degree for a polynomial regression, we should use model selection.