This article shows geometrically where the best estimates for the mean and variance of a normally distributed random vector can be found. We start with a simple question and derive both the geometrical meaning and parameter estimation method from scratch.
Goal
If you’re impatient to know where we’re headed, here are the geometrical insights we will develop in this article:
1) Given observations and independently generated at random by the distribution , our best estimators for and are and such that:

2) More generally, given observations independently generated at random by the same distribution , our best estimators are:
where and are correction factors because as dimension increases, distances increases. The meaning of and are illustrated on the picture below:

Introduction
We can think of a probability distribution as an engine able to generate values at random. A random vector is a vector whose components have been generated by such engine.
Conceptually, it is useful to see the density function for a random vector as a cloud in that indicates the plausible end points for the random vector: the vector is more likely to end in a region where the cloud is dense than one where it is not dense.
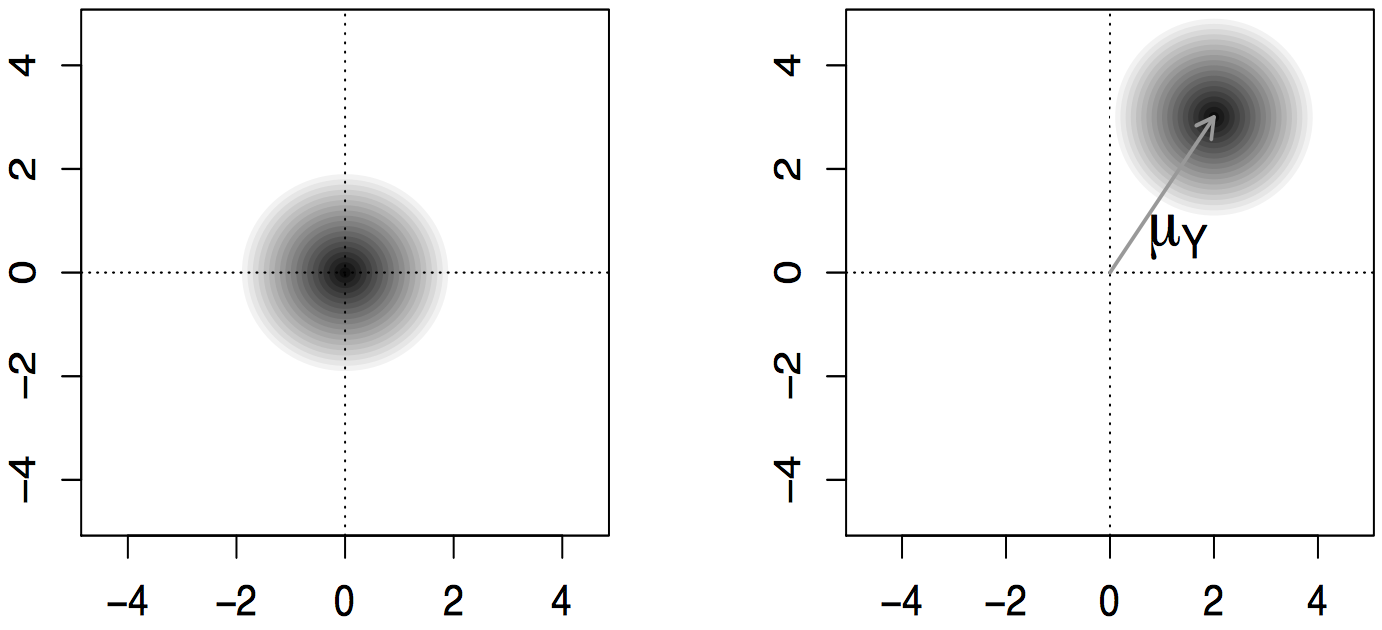 Figure. Density cloud for a vector with distribution on the left and distribution on the right.
Figure. Density cloud for a vector with distribution on the left and distribution on the right.
For instance, the following image shows the “density cloud” of a normally distributed random vector. The components of the vector are generated by a normal distribution, and the visualization shows how this translate to 2D geometry.
Here, the shape of the “density cloud” for the random vector is determined by the parameters of each component: the shape of a normal distribution is controlled by the mean (= location of the center) and it’s variance (= size of the cloud). When the variance for every component is the same, the cloud is a circle.
The shape of the normal distribution (or gaussian distribution) is particularly interesting because it models measurement errors. We can think of it as a cloud that generates a target value with some measurement noise. The variance parameter controls the amount of noise that is added. Among all its desirable features, the distribution is symetric: accross a very large number of measurement, we expect the errors to cancel each others, so that the mean of the sample approximates the real value . We will see later that it has a nice geometrical feature too.
To learn more about the normal distribution, check out this article: A probability distribution to model measurement errors.
Statistics is all about finding the location of the cloud when we have a few observations but we don’t know the parameters and . As we will see, the normal distribution has a nice property that allows us to visualize geometrically the process of estimating those parameters.
Finding the cloud
Suppose for instance that we have two observations and independently generated at random by the same normal distribution .
We would like to estimate the most likely values for the parameters of the cloud: its center and it’s standard deviation . Basically, this means that we will try to find the “best guess” for those values based on the location of our observations.
Our best guess for the center is to place it where it has the highest probability to generate our observations. In statistical terms, we are looking for the maximum likelihood value of .
To find this maximum likelihood location, we need to study the formula for the could’s density more closely.
Since both observations are generated independently, the joint density (= the density for both) is the product which is maximal when minimizes this sum:
You might recognize the Ordinary Least Square equation. This sum has a nice geometrical interpretation because it is exactly the expanded formula for the norm (= length) of the vector :
Geometry
So we are looking for the point on the line of direction that is the closest to .
This point is the orthogonal projection of onto the unit vector directed along the line. We can use the dot product to find the projection coefficient, and multiply by the unit vector to get the projection:
Yeay! We found our best estimate for the center of the cloud!
To ease the transition with higher dimensions, let’s shorten our notation for the vector as where the number stands for the number of components in the vector. So that for instance, . Geometrically, we can see this vector as the diagonal of the -dimensional (hyper)cube of side . The norm of this vector is simply the length of that diagonal: or more generally, . This will prove useful later.
Likewise, let’s adopt a more flexible notation for our unit vector and use for the unit vector directed along . In math notations, this means that: for all values of . Since is a unit vector, we can use it to express the orthogonal projection of . With these notations equation 1 becomes:
This is a vector equation. Let’s find the exact value of our estimate:
We can rewrite this slightly to get the ordinary least square solution :
This result generalizes easily for a higher number of observations. Suppose for instance that stands for a positive integer and that we have observations , …, independently generated at random by a normal distribution . If we write the random vector associated with our observations, we can find our best guess for the center of the cloud by projecting onto . This yields the following best guess for :
From now on, I will use the general notation with to make clear that our results hold in higher dimensions. While reading, feel free to consider that or to visualize the geometry.
Before we estimate the second parameter , let’s write as the sum of the cloud’s center and a deviation vector from the center. It that can be considered as if its components where independently generated at random by a distribution.
Now, I will do a few tricks to show that can be used to estimate the standard deviation parameter . Once done, we will revert back to the geometrical interpretation.
Take unit vectors to form a basis (, , …, ) of space. This means we take a set of axis for space where is the first of them. Note the general random vector which has been realized as . Along each of those new unit vectors, the projection has mean and is distributed according to a normal distribution . We will show that the projection of onto each of those directions yield an unbiased estimator for the variance . Indeed:
We can pool these to get the best estimate for :
If take a unit vector directed along , we know that it is orthogonal to (hence the notation). And we have . Hence, our best estimate for the standard deviation is:
In words, the standard deviation is the length of the deviation vector corrected for the dimension . As I will explain later, this is because lengths are dilated in higher dimensions.
We can replace by the above expression in the formula for the observation vector :
The values and are scale factors due to the dimension of space. Indeed, the length of the diagonal of a square with size is: , for a cube it is and more generally for a -dimensional hypercube it is . This explains the factor associated with which is precisely the direction of that diagonal.
Another way to say this is simply that is the norm of in the -dimensional space.
Likewise, is the norm of in the -dimensional subspace orthogonal to . We loose one dimension because can’t have any component colinear to by definition.
In the special case when the components of are perfect estimators (i.e. when ), the picture reduce to a true -dimensional hypercube and is its diagonal.
When , we have only one observation () and the formula says that our best estimate for the parameter is:
Which means that with only one value, our best guess is to center the distribution on that value. We don’t have enough observations to estimate so it is automatically ruled out of the formula.