This article aims to illustrate what are probability theory and statistical inference in simple terms using a simple to understand problem: drawing colored balls from an urn.
Suppose that you have an urn containing red and green balls that you can’t distinguish otherwise than by their color. You can’t see inside the urn and you draw a ball without looking. Will you get a red or a green ball?
We don’t know if you will get a red ball or a green ball. But if there are a thousand green balls and only one red ball, then it’s very likely that you will get a green ball. But how likely exactly?
Probability theory aims to give a quantitative answer to that question. Given a problem as stated above, probability theory gives you the probability for a given outcome. The probability that you can compute for the outcome may or may not be useful for predicting the actual outcome. It’s usefulness primarily depends on how much you know about the problem.
For instance, if you don’t know anything about the urn except that it contains undistinguishable green and red balls, then there is no reason to expect a green ball more than a red ball. On the other hand, if there are more green balls than red balls, there’s good intuitive reason than the probability for drawing a green ball is greater than that of drawing a red ball.
So that’s the goal of probability theory. Probability theory starts with knowledge and gives you a probability measure for potential outcomes. We shall see later in this article how exactly the probabilities are computed and how we can use them to gauge our expectations.
Statistical inference is concerned with the reverse problem: you have an urn containing red and green balls and you want to know the proportion of red balls. Of course, if the urn is small you can take every ball out and count the number of reds. But if the urn is very large, and if your time is limited, you won’t be able to count every balls. So what can you do?
The method in statistics is to draw a few balls from the urn. For instance, you take out 50 balls. This is called a sample of 50 balls. Then, you study the proportion of red balls in the sample and use it to draw estimates about the real proportion in the urn. You do so by estimating a probability measure that could have yielded the sample. So in a way, statistical inference is the reverse of probability theory: it starts with outcomes and ends with knowledge.
In the following exposion, we will survey the whole mathematical machinery required to solve both problems. For this purpose, we need first to define the rules of probability theory, and apply them to our urn problem. Then, we will take our second problem and go the other way around using statistical methods.
Probability theory: quantifying knowledge
My goal here is not to give a complete and rigorous construction of probability theory. Instead, I will give the most important rules and explain what they correspond to and how we can use them. We will then illustrate their use on our urn problem.
There are several constructions of probability theory, based on various mathematical objects (for instance, sets or propositions). These constructions differ in their philosophical view, but they all yield the same rules to compute probabilities, which in practice is what really matters.
Here are the rules. If you already know them, feel free to jump to the next section.
We will use capital letters to denote propositions. For instance: = “There is an urn. It contains red and green undistinguishable balls. We can’t see the color of a ball before taking it out from the urn”. Another example: = “My next draw from the urn yields a red ball”. The proposition can be true or false. For instance, I can draw a red ball from the urn, and was true. Or I could have drawn a green ball and was false.
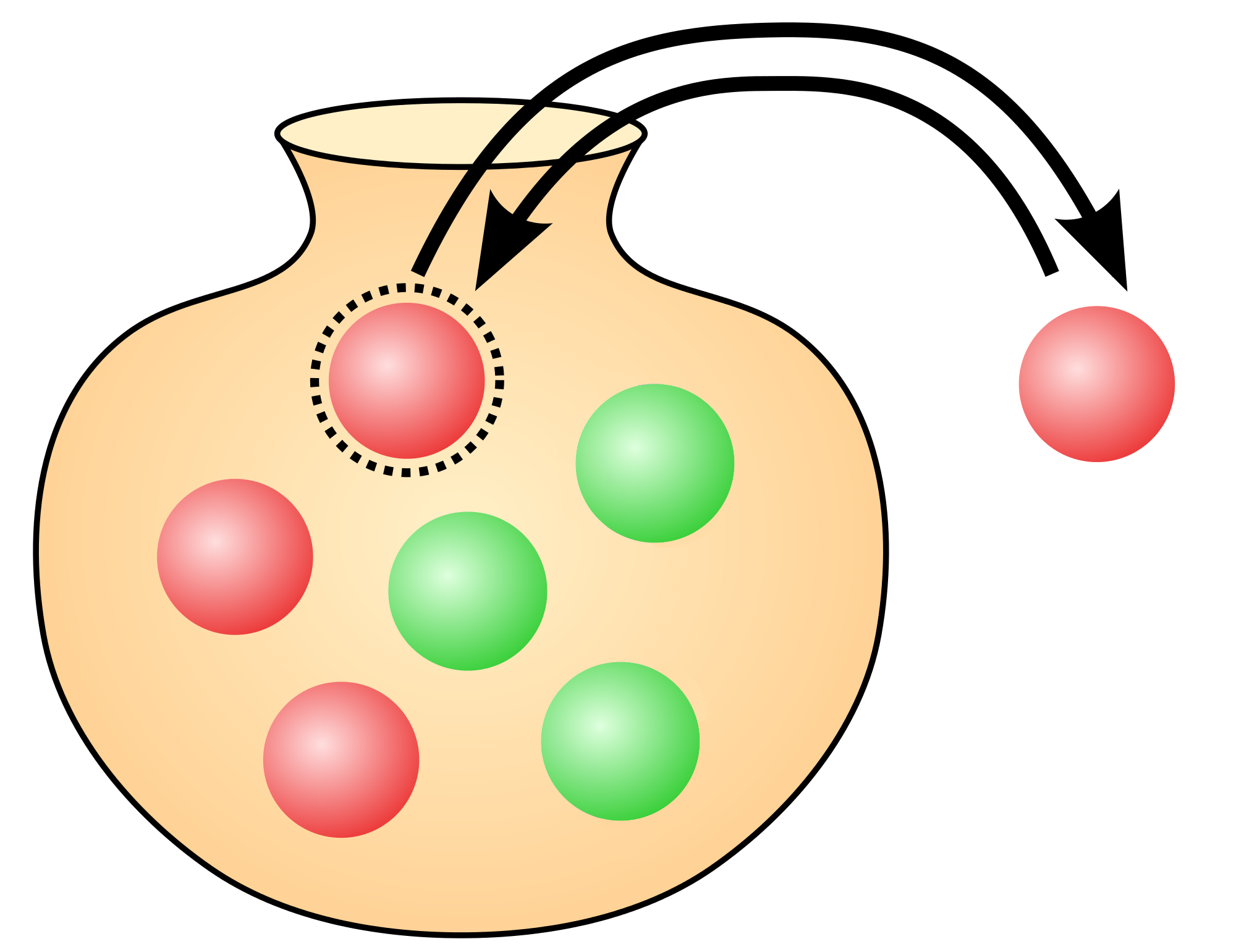
Before I draw a ball, I don’t know whether is true or false. But I can measure my confidence that it will be true. We will measure our confidence in percent () and use the following notation:
To say that we are confident that is true given our prior information . To be clear, this means that we know is true and that we estimate our confidence in as .
Or we can be only confident that is true, and in that case we note:
If I have more information about the problem, this can update my confidence estimate. For instance, if I know that the proposition = “There are only red balls left in the urn” is true, then I’m becoming confident that I will get a red ball. Which we note:
Notice how we take new information into account by inserting it after the vertical dash .
Given a proposition, I can write a bar on top of it to say the opposite. For instance = “My next draw from the urn does not yield a red ball”. I can estimate my confidence in from my confidence in :
Which makes sense because if I’m confident that is true, then I’m confident that it is false. In other words, I’m confident that is true.
Given a second proposition, for instance = “My second next draw from the urn yield a red ball”, I can estimate my confidence that both and will be true like this:
- first I estimating my confidence in one:
- then, I consider it true and estimate my confidence in the other: .
So, if we note the proposition stating that both and are true, I can estimate my confidence in it by:
Or, I can do it the other way around:
Where the dot is used to mean “multiplication”.
Having established these two rules, I can compute my estimate that one of or is true using the logic formula for “or”: . If you don’t know what this formula means, don’t worry. The only thing you need is the resulting rule for computing the estimate of ( or ) that we note :
Let’s put this formula to test with some numerical values. Before that, let’s suppose that our estimate for does not depend on . That is, our confidence in will be the same, whether we know is true or not. We can note this in the theory simply by assigning the same value for and .
| description | estimate | value |
|---|---|---|
| estimate in | ||
| estimate in | ||
| same when we know | ||
| use formula for “and” | ||
| use formula for “or” |
So, if I’m very confident in but not confident in , probability theory says that I should be very confident that either or is true, since . It also says that I should not be confident that both and are true since . Which make intuitive sense when you think about it.
Application to our urn problem
We will now use probability theory to estimate what we can expect when we draw colored balls from an urn. This looks like a toy problem but many fundamental aspects of probability theory and methodology can be illustrated with it.
Equiprobability from symmetry argument
As previously, let be the background information stating our problem: = “There is an urn. It contains red and green undistinguishable balls. We can’t see the color of a ball before taking it out from the urn”.
The question of interest is: “What is our confidence that we will draw a red ball?”
With our current state of knowledge, there is no reason to expect a red ball more than a green ball. A symmetry argument can help us see why: since the information about the color “red” and the color “green” are completely symmetric in , our estimates should be completely symmetric too.
If we note = “we draw a red ball” and = “we draw a green ball”, according to our symmetry argument above:
Suppose that we decide that we will draw a ball from the urn, and call this fact = “We draw a ball from the urn”. There are only two possible outcomes: either the ball is red and is true, or the ball is green and is true. In that case, we are confident that either or will happen:
Using the formula to expand the probability, we get:
Of course, information didn’t change anything to our previous symmetry argument. Using both equations, we can deduce a definite numerical value:
And that’s it! Using pure logic, we managed to get definite confidence estimate for the outcome of our draw. Our current state of knowledge doesn’t teach us much about the color we will get, so both color are as likely. This is already a great achievement because it shows that numerical values can be computed from logic, and doesn’t have to be guessed arbitrarily. But this is also a bit deceiving because it doesn’t help much. Let’s see what we can learn if we know a little more about the content of the urn.
Using the proportion of red balls
Suppose that we know the content of the urn: = “the urn contains red balls and green balls. The total is ”. We can use this information to update our probability estimates.
How can we compute the probability ? We can formulate the problem differently and reuse a symmetry argument as before. The new information tells us that there are balls in total. In our heads, let’s arbitrarily number the balls. Call the first ball , the second , … and the -th ball for .
We will turn our attention to a new but highly related problem: We draw a ball from the urn, and we ask the probability that this ball is the ball :
The color of the ball becomes irrelevant in the new problem. So what our background information () tells us is this: “the urn contains undistinguishable balls, we draw a ball”. This information is completely symmetric with regards to our index . With the same reasoning as in the previous section we know that each will be accorded the same probability and that the sum of our probability estimates for the is Therefore:
Now, let’s reorder the balls so that the first are reds and the last are greens. The probability that we draw a red ball is the probability that we draw any of the first balls:
And using the formula for “or” multiple times, we find:
So here is what we have so far: our probability estimate that we will draw a red ball from an urn containing balls, of which are reds is: .
But this probability estimate is a measure of our confidence based on the partial information we have. Therefore it doesn’t make sense to try and “verify” it by drawing multiple balls from the urn. To say it differently: it is a confidence estimate, not an expected frequency.
What we can do, however is draw a sample containing multiple balls from the urn, and compute the most probable fractions of red balls in this sample. Then, we can compare the most expected fraction with the actual fraction in the sample.
Computing the most expected fraction
In this variant of the problem, we draw a sample of balls from the urn. And we wonder what is the most likely number of red balls in our sample.
In order to use probability theory to solve our problem, here is an updated version of our background information: = “An urn contains balls, of which are reds. The others are green. We draw a ball from the urn, then replace it inside and shake the urn times.”
We will first compute the probability to obtain a given ordering of red and green balls. Then, we will use a symmetry argument to show that whatever the ordering, its probability only depends on the number of red balls in it. Finally, we will use the “or” rule to compute the probability to obtain red balls.
So let’s start by computing our probability estimate for drawing the balls in a given order. We will use the following notation: = “the -th ball is red” and = “the i-th ball is green” and we want to compute the probability that the first balls are red and the last are green. To save some keystrokes, let’s note this estimate :
The long list of above means that: draw is red, every draw is red until draw , then draw is green and every draw is green until .
Since we replace the ball in the urn each time, a draw is independent from the previous ones. Using the formula for “and”, taking this independence into account:
According to the previous section, and , so:
Actually, drawing the balls in a different order would reorder the factors without changing their value since the draws are independent from each other. But since multiplication is commutative, this won’t change the result. Therefore, as long as the number of red balls is , the probability to obtain a sample with balls, whatever the order is .
Now, we can use the “or” rule to compute the probability to obtain a sample with of whatever order. Indeed, if we list all the possible orderings with red balls, we can see that obtaining red balls in a sample means obtaining the first ordering or the second ordering or any of those we listed. Therefore, it’s a big “or” that we can split using the “or” rule.
Let’s note =”The number of red balls in the sample is ”. And let’s note =”The sample has order ” where ranges from to the size (noted ) of our list. We have:
Since we can not obtain two orderings at the same time, this reduces to:
The computation that follows is more mathematics oriented that the rest of the article, so I won’t dive into the details. If you don’t understand everything, it’s no big deal, just accept the result of the computation and keep reading. We can use a result from discrete mathematics to compute the size of our list:
Therefore:
The value of for which we are the most confident is the value where the above formula has maximum value (details). Actually the formula has 2 such values, so we have two candidates:
and
Which means that the most likely fraction of red balls is either:
or
As we can see, this is very close to the fraction of red balls in the urn but not equal. The additional term decreases as gets bigger and bigger. And if we drew an infinite number of balls from the urn, this term would vanish, meaning that the expected fraction is the same as that of the urn. Of course, in real life it’s impossible to draw an infinite number of balls.
While it made no sense to compare our probability estimate to draw a red ball to the proportion of red balls in a sample, it now makes sense to compare the most likely fraction of red balls to the fraction in a sample. As you can see, the most likely fraction is very close to our probability estimate. But conceptually, both are different and there could very well be more complex situations where both numbers are very different.
The three derivations above were meant to illustrate how probability theory is used. Let’s now turn the problem upside down: we have already estimated the most likely number of red balls in a sample given the number of red balls in the urn; we will now estimate the number of red balls in the urn from the number of red balls in the sample.
- Probability: urn sample
- Statistics: sample urn
Statistical inference
The remaining of this article is concerned with hypothesis testing. Given an hypothesis =”there are red balls” about the urn, we will use a sample =”we drew balls and and them were red” to estimate the hypothesis.
The previous sections took the hypothesis for granted and computed a propability estimate that the hypothesis would yield the sample (i.e. the probability to get red balls among draws, given that there are red balls in the urn). In equation terms, we computed:
Where, as before, stands for some background information.
We will now compute a probability estimate for the other direction:
Using the formula for the “and” rule we see that:
Therefore:
From discrete to continuous
Note: my goal is not to provide a rigorous definition of continuous probability, so I’ll skip over the details.
Recall our formula for the probability estimation for given the sample :
We will now take the following hypothesis: =”The fraction of red balls in the urn is ”, so the formula becomes:
Since we are concerned with the hypothesis , we would like to remove from the equation. We can do this using the following insight.
Digression
Suppose that we have propositions , …, such that at least one is true, and no two of them are true at the same time:
| and | , |
For instance, = “the fraction of red balls in the urn is ” has this property. If is true, then is necessarily false. Likewise, there is at least one number that is equal to the fraction of red balls in the urn.
Then, we can write:
and:
or in shorter form:
if we have an infinite set of hypotheses, the sum becomes an integral:
Using this formula in the expression for , we find:
According to our computation of above, the probability to obtain a sample of size containing red balls given hypothesis is:
If you consider the fraction to be and compare with the formula given for above, you will see that the formula is the same in different notations.
And thus we get the complete formula:
Where it only remains to find a numerical value for . But since in the absence of data nothing in the background information tells us anything that would favor one hypothesis over the other, we will follow a symmetry argument as we did before and assign the same probability estimate for every . Since at least one of the must be true, we know that their “sum” is :
And since all the have the same probability estimate, we deduce:
Our probability estimate for hypothesis is thus:
After some math involving the Eulerian integral of the first kind, we get:
which is maximal for .
So, the most probable fraction of red balls in the urn is , which is the fraction of red balls in our sample. Compare this with our result from probability theory:
- Probability theory says that:
- if the fraction of red balls in the urn is
- then the most likely fraction in the sample is
- for a constant
- Statistical inference says that:
- if the fraction of red balls in the sample is
- then the most likely fraction in the urn is
But how likely is the most likely fraction?
Interval estimate
We know the most likely value for , which is called a point estimate. But we would like to know how likely this value is.
To quantify this, we can use the de Moivre-Laplace theorem to find that is a Gaussian distribution (also called normal distribution) of mean and variance as long as and .
Here is a graph (made with python) of both functions for and :
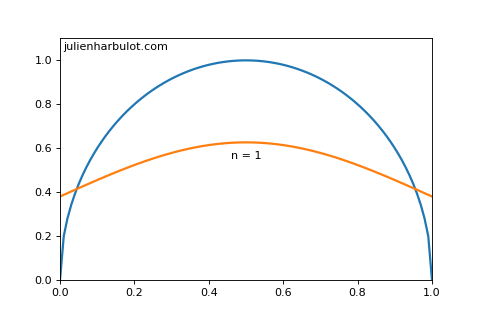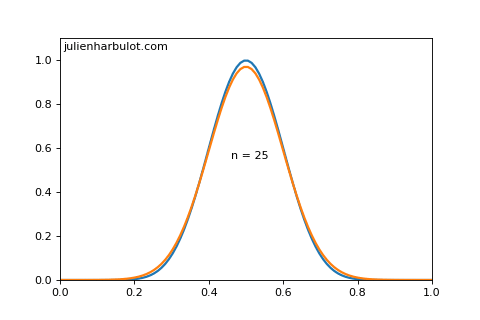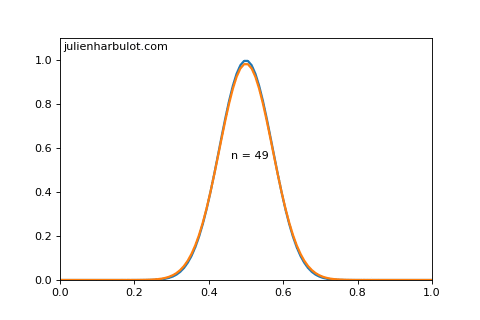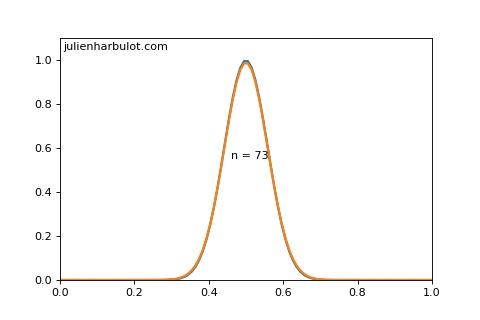
From this we can estimate intervals for our confidence level:
- 50% probability that the true value of the fraction is contained in the interval ;
- 90% probability that it is contained in ;
- 99% probability that it is contained in .
Read next
If you want to see how the rules of probability given above can be constructed, check out this article: Probability, the logic of uncertainty